I'm no script virgin. I'm an armchair linguist who knows the Japanese and Korean scripts well, and has a nodding acquaintance with many others. I'm no longer shocked by letters and pieces thereof magically disappearing or changing shape or engaging in shameful public acts with each other. I've come to expect baroque and archaic rules and long lists of exceptions. But Tibetan's pure, shameless, in-your-face weirdness still managed to shock me.
Probably after studying Tibetan for ten years this would all seem obvious and natural to me. Actually, at this point I've studied it for all of one weekend, albeit an intensive 20-hour weekend with a whole semester's worth of Tibetan crammed into it. I thought I would be learning basic Tibetan but what I soon found is that it takes 20 hours just to learn Tibetan orthography. It's not until Tibetan II that you even get to basic grammar and vocabulary.
What's so strange about Tibetan? After all, they start off with an alphabet like just about every script. There are thirty characters, arranged in a neat 8x4 matrix, the two cells on the bottom right being empty. And there's a great deal of logic in the way the matrix is structured.
For instance, the first row contains "k"-like sounds, made in the throat. The second "ch"-like sounds, made on the roof of the mouth, the third dental "t" sounds, the fourth labial "p" sounds, and so on.
And the first column contains the basic unvoiced sound (for the first row, "ka"), the second a breathy, aspirated sound ("kha"), the third the voiced version ("ga") and the fourth the nasal variant ("nga"). This layout mimics the Sanskrit used as a model for the Tibetan script.
Here's how the matrix looks:
ཀཁགང ka, kha, ga, nga
ཅཆཇཉ ca, cha, ja, nya
ཏཐདན ta, tha, da, na
པཕབམ pa, pha, ba, ma
ཙཚཛཝ tsa, tsha, dza, wa
ཞཟའཡ zha, za, 'a, ya
རལཤས ra, la, sha, sa
ཧཨ ha, a
Tibetan is a tonal language, but (thankfully) not in the Chinese fashion. Instead, each syllable, to oversimplify somewhat, has either a high or low intonation. And another elegant aspect of the arrangement of Tibetan characters into the matrix above is that in general the first two columns take the high, the last two columns the low intonation. Whether high or low, Tibetan tones do not go up or down, but stay "flat".
The lower rows depart from the regularity of the first five, but remember, the inventor of the alphabet was not inventing the sounds, just inventing ways to organize and represent them.
Can't see the characters in the table, or see empty squares instead? Then something is wrong in your universe of browsers/encodings/fonts/renderings. Your browser needs to handle Unicode, since that's how I've specified the Tibetan characters. And it needs to have access to Tibetan fonts, most likely as part of a Unicode font such as MS Arial Unicode. Sorry, we're not going to spend any more time here debugging your Tibetan display problems. You should visit the Omniglot Tibetan page, which shows the matrix, the vowel marks discussed below, and examples of Tibetan writing.
Back to Tibetan spelling. The thirty characters above can be used as is, as long as you put the a little dot after them indicating that that's the entire syllable (or "morpheme" in linguist-speak). So ག་ is kha, the Tibetan word for "mouth". We're cooking!
Each character has a built-in "a" sound (pronounced "ah"). So how would we get something like ri, for "mountain"?
Tibetan handles vowel orthography in a highly regular way. There are just five vowel sounds including the built-in "a", the others being "i", "u", "e", and "o", and each has its own symbol, placed above or below the character in question:
ི gigu, a hook above giving "i"
ུ shabkyu, a hook below giving "u"
ེ dreng-bu, a kind of accent grave, giving "e"
ོ naro, a mark above giving "o"
So ri or "mountain" would be RA with the gigu hook above it. Unfortunately, I can't show that to you easily on this web page. The problem is that Unicode has defined only components of Tibetan script elements, as opposed to composed glyphs. (Tibetan occupies a single 256-byte "page" in the Unicode code space.) And no web browser has the logic required to compose these components on the fly into the so-called stacks or "grapheme clusters" (the "graphemes" here being the RA and the I) that are required. There's a Unicode character called COMBINING GRAPHEME JOINER which in some better world might do something useful, but it doesn't seem to. ZERO WIDTH JOINERS possibly could be interpreted in a friendly way but they aren't. To see a whole bunch of decomposed and thus completely weird-looking Tibetan text encoded using Unicode see the Tibetan Unicode Test Pages. I will studiously avoid getting involved in the religious wars as to whether or not Unicode 29.0 should define all grapheme clusters as individual code points, of which there would be several thousand.
In any case, at the moment only dedicated environments are capable of correctly rendering Tibetan. There is a hack involving MS Word. There is a Java app. Emacs supports entering and displaying Tibetan. For the Macintosh, there is the Tibetan Language Kit. All these alternatives involve a home-grown encoding together with a more-or-less custom fonts. In some cases, it may be possible to embed the glyph information into a web page, marking the Tibetan portion for rendering with the Tibetan font, allowing Tibetan to be displayed on "normal" web pages, assuming platform and browser compatibility.
The elegant architecture of Graphite should permit a Tibetan implementation but no-one has gotten around to doing it yet.
So on a web page like this I can't show you a "ri", except as a graphic.
This all seems boringly regular. But actually, this is precisely the point at which Tibetan spelling begins to get extremely hairy. Since this article cannot give a complete description of Tibetan orthography, let's just jump right in with a real-world example.
We'll use the word pronounced drup (or droop in pseudo-phonetic notation, low tone), which is the past tense of the word meaning "accomplish". Here we go: using English transliterations for each Tibetan character, it's written BA SA/GA/RA/U BA SA. And there you have it: drup. I've used spaces to separate the four "pieces" which are used to write this syllable. Bring up the image of how drup is written in a separate window and you should be able to follow the discussion more easily. You can see the four pieces, arranged left-to-right. Notice the second "piece" is stretched out vertically. That's because it's a "stack" which contains the SA/GA/RA/U arranged vertically. Some people might prefer to call this a "grapheme cluster".
OK, let's take this one step at a time. The first character is the one for BA. That's one of those thirty basic characters used in Tibetan. Why BA? Well, actually, no one knows. It's silent, and has nothing to do with the pronunciation of the word. This character is a prefix, one of several that can so function, all of which are silent when they do so. It is a prefix to the "root" character which follows.
The next piece is the tall, stacked "root" letter. Placed to the right of the BA we just wrote, it begins at the top with the the character SA. But technically, this character is a superscript, and is also silent, completely unrelated to the pronunciation of the word.
Finally we get to the character for GA. This is the heart of the stack and the entire syllable drup, and is written underneath the SA. Now to form Tibetan syllables, you mostly string the basic characters together left-to-right. But the "main" piece in each group can be a "stack", where a bunch of basic characters are arranged top-to-bottom; that stack then fits into the left-to-right sequence of the other pieces. In other words, the individual basic characters in Tibetan spread out both to the left and right and up and down from the central root character. The GA character we just added is that central root character. As we'll soon see, the GA does have a relationship to the word we are trying to spell (drup), although it's tenuous in the extreme.
Underneath the GA we write a variant of the character for RA. This is a subscript. The alert reader may guess, correctly, that the "r" sound in RA accounts for the "r" sound in the word drup. What he or she could not deduce is that it also changes the "g" sound of the GA above into a "d" sound, yielding "dra". There's no reason for this--it's just the rule. But at least we seem to be making some progress towards drup.
Still working on the same stack, we now add to the bottom the final element, the curly shabkyu, the vowel character mentioned above which changes the intrinsic "a" sound to a "u" sound, giving us "dru".
We're finished with the stack. Next we move on to the third element of the syllable, which is the character BA again; this time it's not silent, but rather puts the final "p" on the word drup. And then we're done, right?
Not so fast. We still have the final SA, another silent character, the fourth left-to-right piece of the syllable (the so-called second suffix, present in some but by no means all syllables). Then, finally, we really are done. We just write the little dot called the tsek, which terminates the entire four-piece syllable. Voila.
A scholar named Wylie came up with a way to uniquely transliterate Tibetan into Roman characters, completely round-trippable. (The word drup in "Wylie" is BSGRUBS.) This provides a handy and widely-used mechanism for inputting Tibetan into word-processing programs. Western Tibetan scholars are said to be able to read Tibetan directly from such transliterations. There is no reported research on what the effect on their brains of learning to do so was.
Of course, the Tibetans themselves need a way to spell to each other. They've come up with an elegant approach, where each component is given, followed by its position in the stack if applicable and then cumulative phonetic result. So our drup example would be spelled in Tibetan as:
BA O (meaning silent) SA GA ta (meaning below) ga (pronunciation so far) RA ta (meaning below) dra (pronunciation so far) shabkyu ("u" vowel) dru (pronunciation so far) BA drup (pronunciation so far) SA drup (final pronunciation)
Drup is hardly a unique example in terms of the exceptions and special rules involved. Write DA/RA? That's cha (bird). How about ZA/LA? That's da. A final NA puts the "n" sound on the end of the word, but also changes the preceding vowel. Or, you could do the same thing by just putting a little circle on the top of the main stack in the syllable. And so on, ad inifinitum. Don't even get me started on the variant characters used for Sanskrit borrowings.
Speaking of Sanskrit, which I know virtually nothing about, Tibetan inherits major portions of its orthography from that language, and to that extent shares with modern-day descendants such as Devanagari. It's possible writers of those languages would not find Tibetan to be quite as "dysfunctional" as this newbie did. Having said that, Sanskrit does not have the huge clusters, or the frequent silent characters of Tibetan (although it does have its own set of major difficulties, including many more characters and its rich grammar).
So what is the deal with these silent characters anyway? They clearly play a major role in resolving homonymal ambiguity in Tibetan. For instance, the word for "I, me" is pronounced "nga" and written NGA as expected, while the word for five" is also pronounced "nga" but is written LA/NGA with a silent LA. Fine and possibly useful, but other languages manage to deal with the same kind of ambiguity without resorting to such tricks. Those tricks make the learning curve markedly steeper, not only for adult foreign students but for native-speaking children as well. If the silent letters had some other meaning, perhaps semantic, it would be more understandable, but they appear not to.
It appears that in general these silent letters reflect archaic pronunciations. This theory is supported by the observation that the word "lama" (guru) is written with a silent leading BA, and in some dialects is actually pronounced "blama"./p>
How did Tibetan orthography get to be such a mess? Probably because it basically hasn't been reformed in the millennium-and-a-half since it was invented by the legendary Thon-mi Sambhota, although it seems to me that it must have been pretty baroque even back then. Just imagine trying to write English in an ur-Germanic script from 1400 years ago, with the added restriction that words today must be spelled exactly as the words they were derived from were.




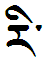{kind=link}
{kind=link}